
Book Reco
Online Bookstore with a Hybrid Recommendation Systems
An online bookstore featuring a hybrid recommendation system. The platform leverages content-based and collaborative filtering algorithms to provide personalized book recommendations based on user preferences, purchase history, or ratings.
Deep Dives
Covering technical aspects, such as architecture, design decisions, and implementation details.
Case Studies
Information Overload
The overwhelming abundance of book data (retrieved from the Gramedia API scraping) makes it difficult for users to find relevant books.
The Need for Personalization
Modern e-commerce requires a engine capable of understanding the unique preferences of each individual.
Technical Challenges
Building a system that remains lightweight on the web front-end while intelligently handling heavy matrix computation on the back-end.
The system is intended for research and demonstration of recommendation techniques and includes tools for scraping, preprocessing, training, and serving recommendations.
System Architecture
Main Application (Laravel 12)
Handles transactions, book data management, payment gateway (Midtrans) integration, and Admin panel.
Model Service (FastAPI)
A dedicated Python engine for Data Science processes (Training & Tuning).
Containerization
The entire ecosystem is wrapped in Docker containers to ensure scalability and ease of deployment.

Recommendation System Methods
Using a Hybrid Recommendation System approach.
Content-Based Filtering
Utilizes book metadata (title, author) processed with TF-IDF Vectorization and Cosine Similarity to identify product similarities.
Collaborative Filtering (Model-Based)
Implementing Singular Value Decomposition (SVD) to extract latent factors from user-item interactions (ratings and transaction quantities).(Diedit)Pulihkan teks asli
Data Science Flow (Pipeline)
Starting with the data acquisition process (scraping), followed by data preprocessing (data cleaning), the model training and tuning phase (Grid Search), and finally the serving phase via a microservice API integrated with the e-commerce website.

1. Data Acquisition
Scraping data from Gramedia's public API.
2. Preprocessing
Cleaning book metadata data in Laravel.
3. Model Training
Sending the dataset to the microservice via the API.
4. Evaluation
Calculating RMSE and MAE metrics to ensure model accuracy before deploying to production.
5. Serving
Recommendation results are displayed on the frontend using Inertia.js (Vue 3).
The system can be configured to automatically train models at specific intervals whenever book, transaction, and rating data changes, ensuring users receive recommendations based on the most recent interaction patterns.
Dataset/Materials and Visualization
1. Data Source
Dataset collected through legal web scraping techniques on Gramedia's public API, resulting in thousands of book metadata items including title, author, cover image, ISBN, price, and category.
2. Materials
User interaction dataset (dummy/transaction simulation) including user ID, book ID, rating score, and purchase amount.
3. Visualization
Error Analysis: Visualization of the decrease in RMSE and MAE during the hyperparameter tuning process (Grid Search).

Top-N Recommendations: Visual representation of the most frequently recommended books compared to best-sellers.

Analysis Results & Insights
1. Model Evaluation & Baseline
Based on test results on simulated (dummy) data, the SVD model produced a relatively high RMSE value. This was identified as a result of the high level of sparsity (rare data) and random rating distribution in the dummy data, which does not fully reflect complex (logical/patterned) human behavior patterns.
2. Pipeline Stability
The key insight is not the absolute RMSE figure, but rather the stability of the pipeline. The system has proven capable of automating the end-to-end process: from transaction aggregation in Laravel, sending data to FastAPI, to consistent prediction calculations despite high data variance.
3. Cold-Start Effectiveness
The popularity-fallback strategy ensures a high retention rate for new users even when preference data is not yet available.
4. Strategy Comparison
Analysis shows that under conditions of limited/random data, the Content-Based Filtering approach provides more qualitatively stable results (title relevance), while Collaborative Filtering acts as a user-relationship discovery engine that becomes more precise as the density of real transaction data increases.
Potentials
1. Application in Local/Independent Bookstores
Helping small bookstores digitize their inventory and have a recommendation system as sophisticated as large marketplaces (Amazon/Gramedia) with efficient infrastructure costs (due to the use of microservices).
2. Campus Digital Library
Increasing student interest in reading by recommending books based on the borrowing history of similar students in the same major.
3. Personalized Marketing Tool
This system can be integrated with Email Marketing or Push Notifications to offer books that customers "truly desire," thereby increasing the Conversion Rate (CVR) for business partners.
4. System Scalability
The FastAPI-based architecture allows this system to be developed into a SaaS (Software as a Service) platform that can be used by multiple book e-commerce partners simultaneously.
Conclusion
This project demonstrates that Data Science technology can be seamlessly integrated into a functional production web application.
Attachments
Additional resources, such as documents, diagrams, and supplementary materials.
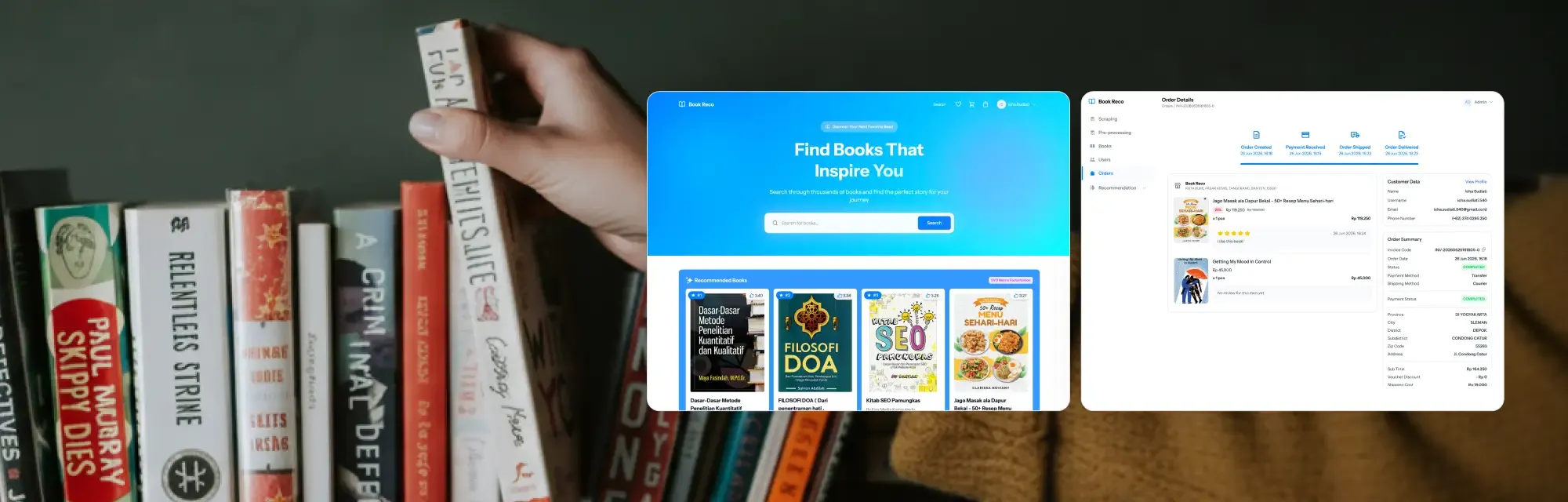
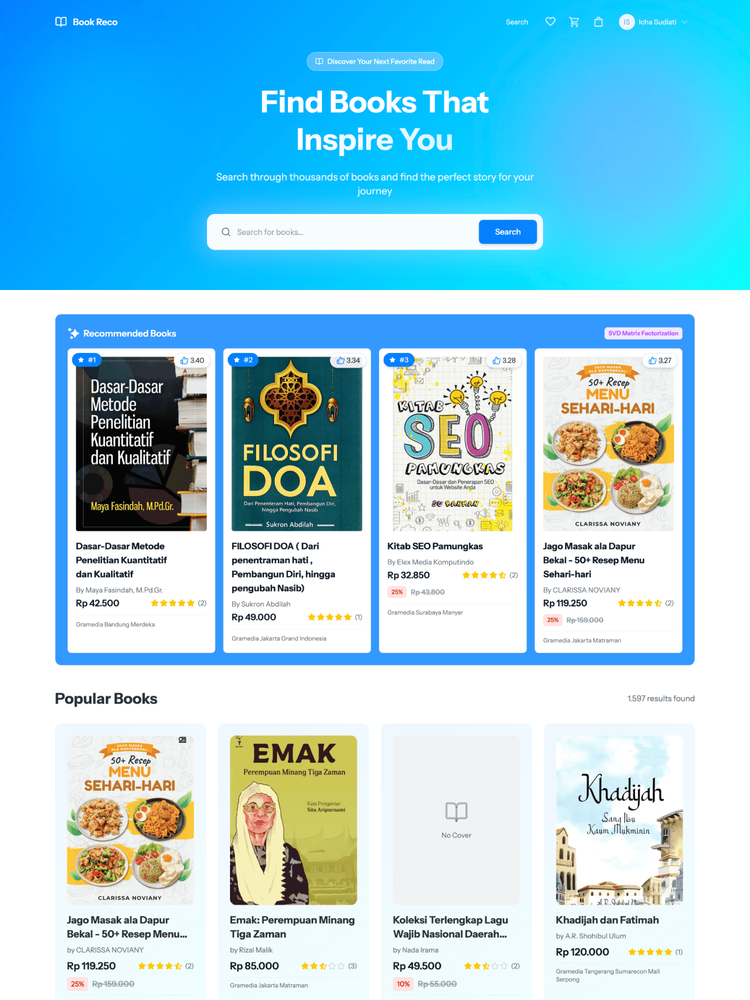
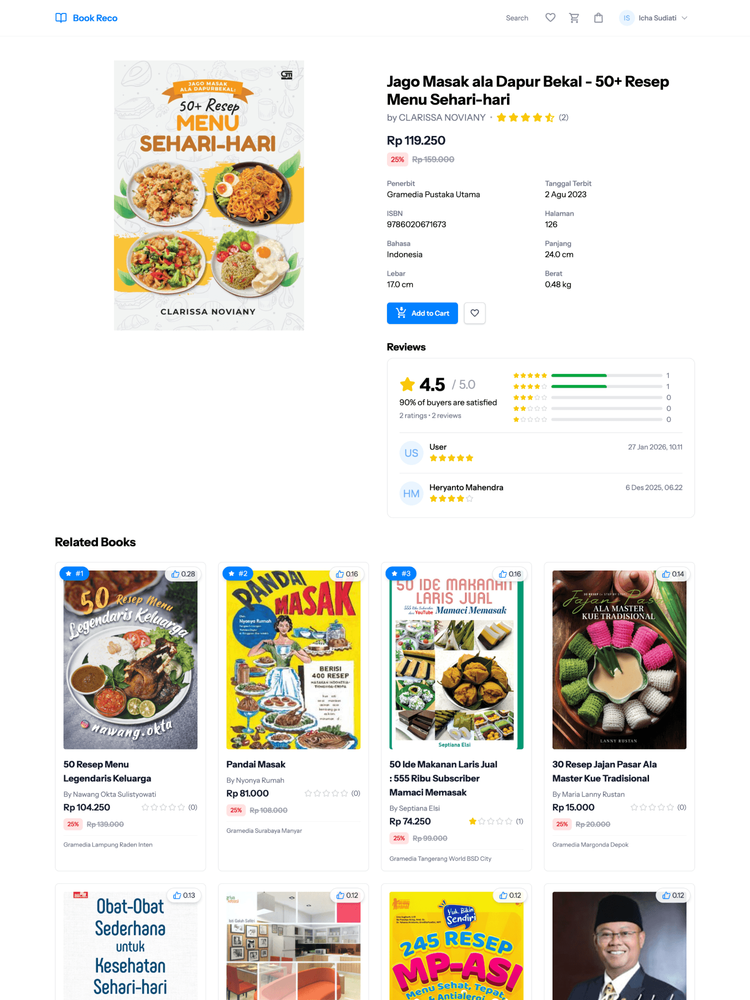
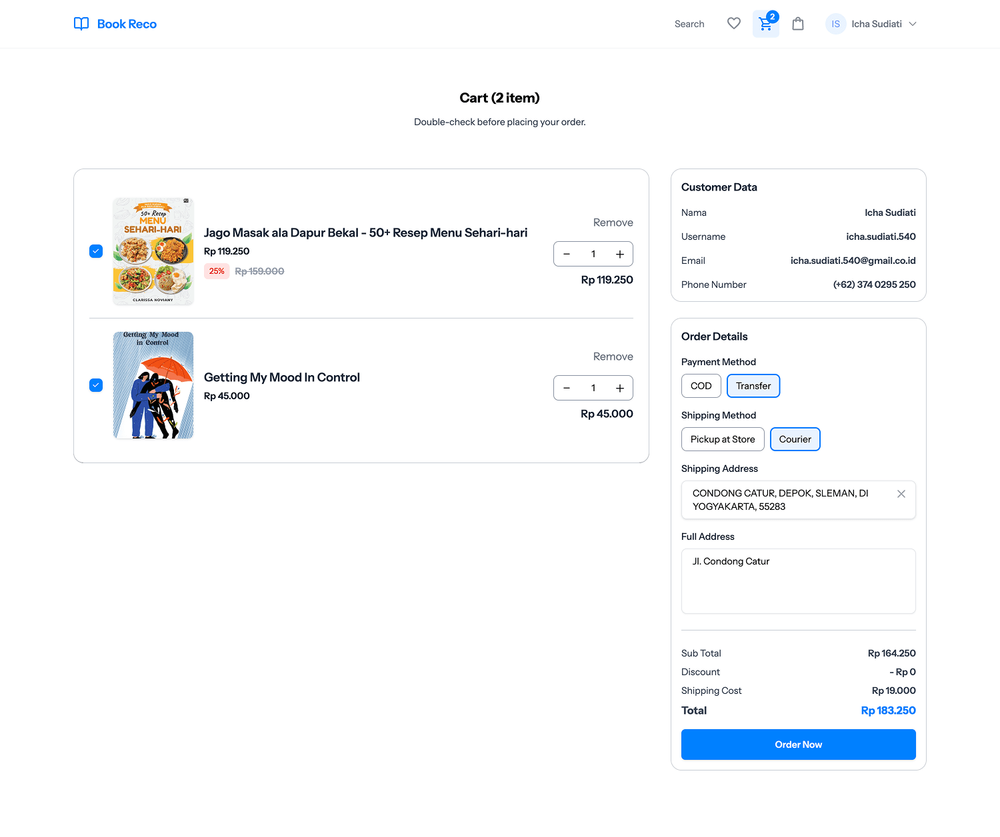
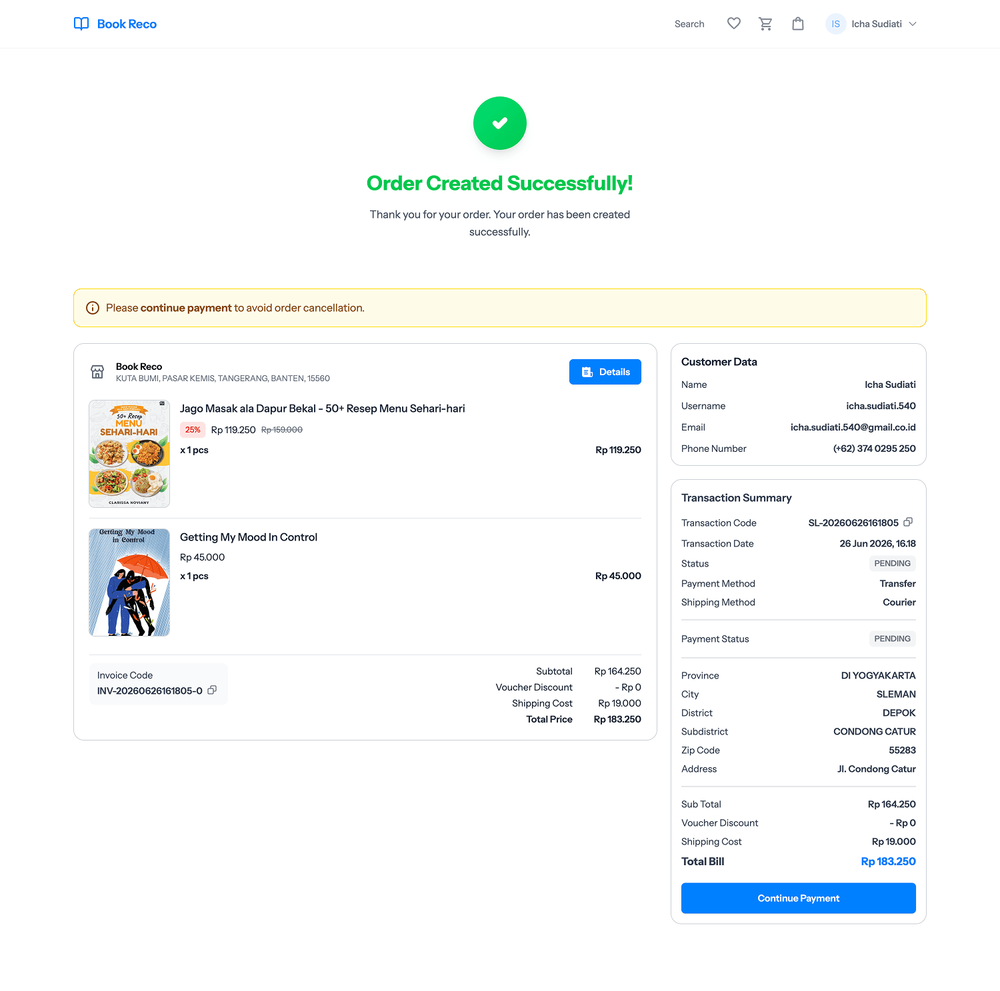
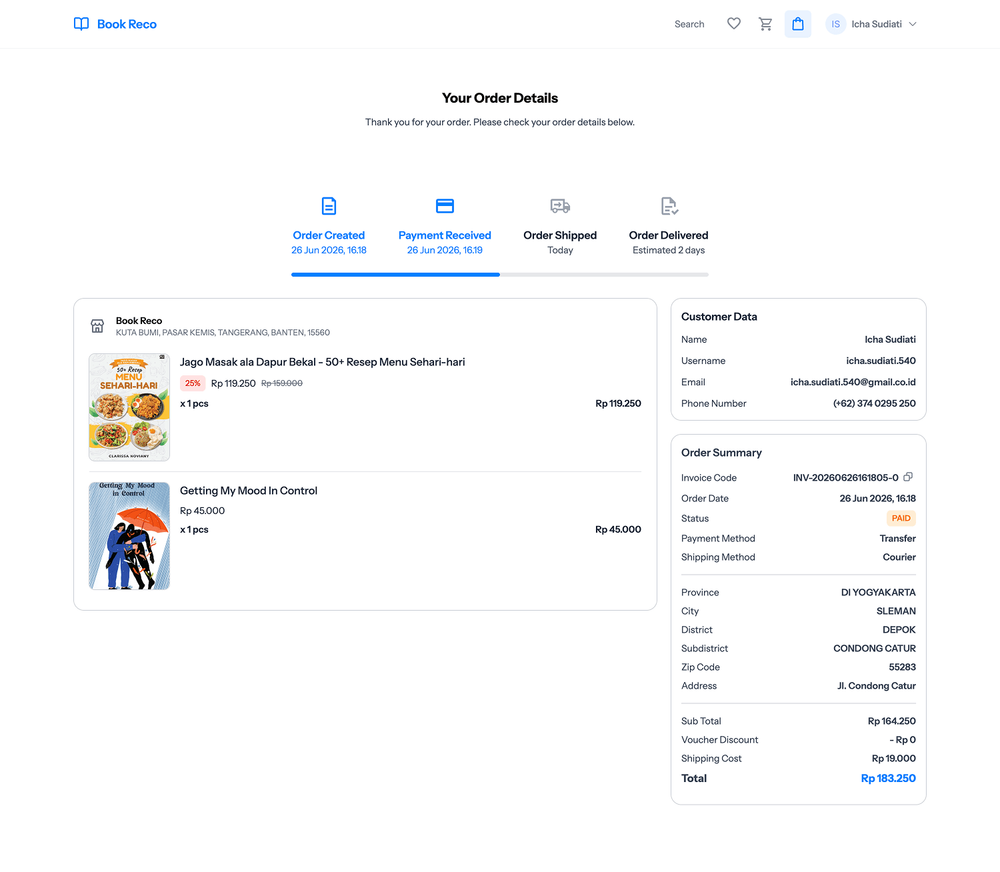
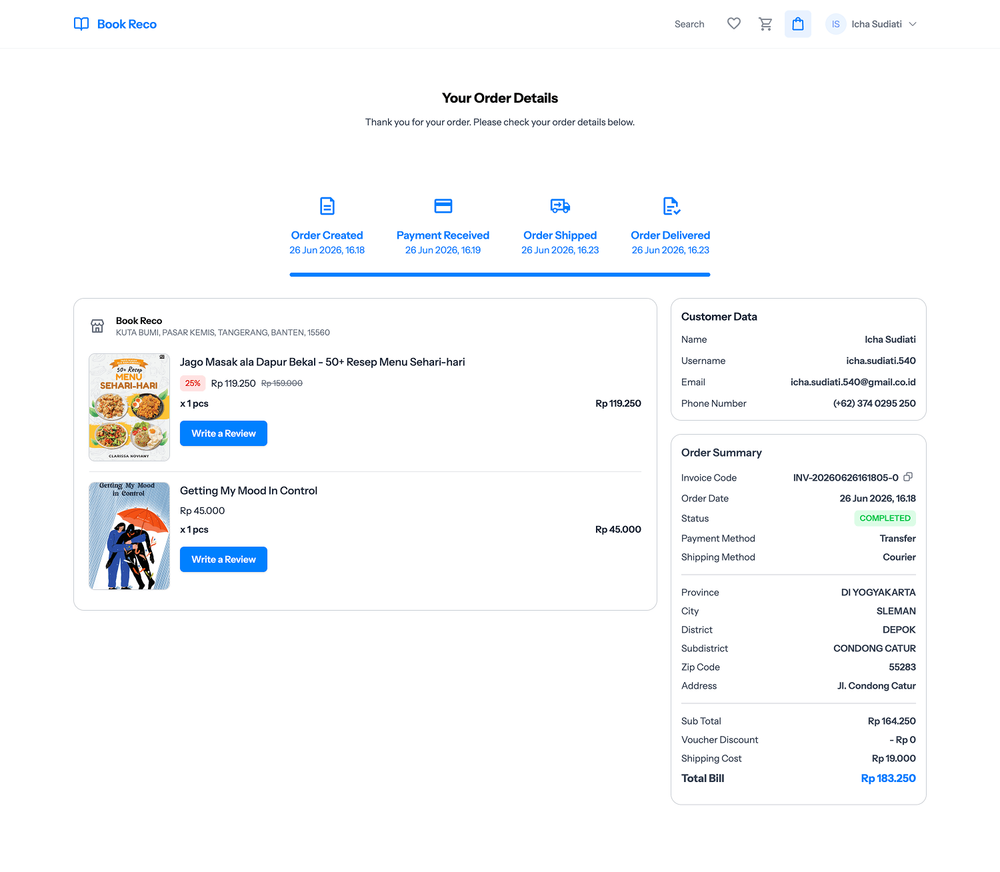
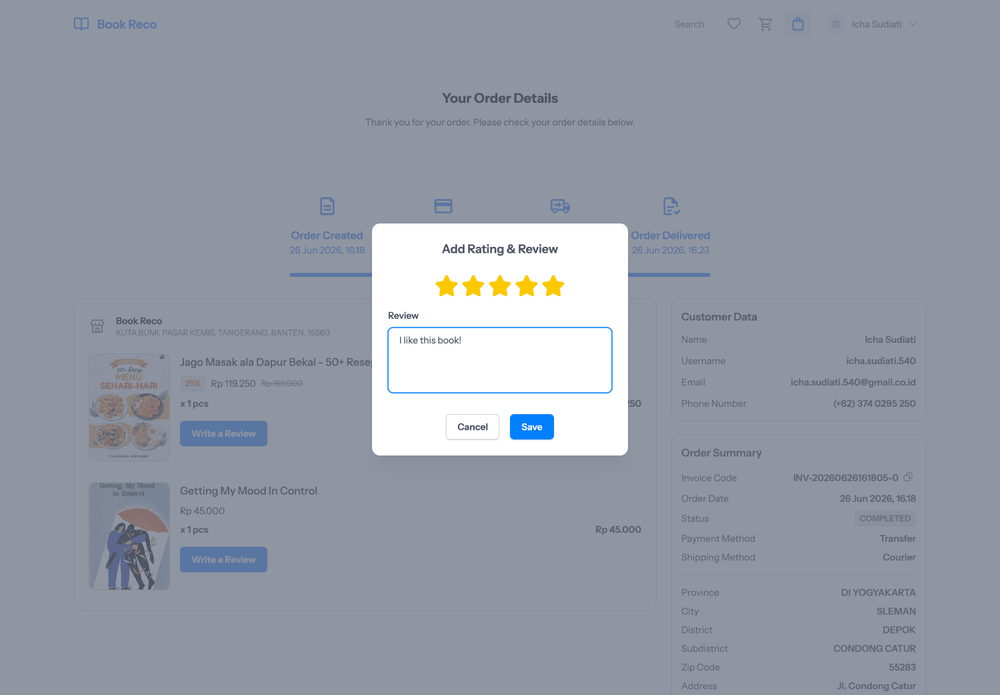
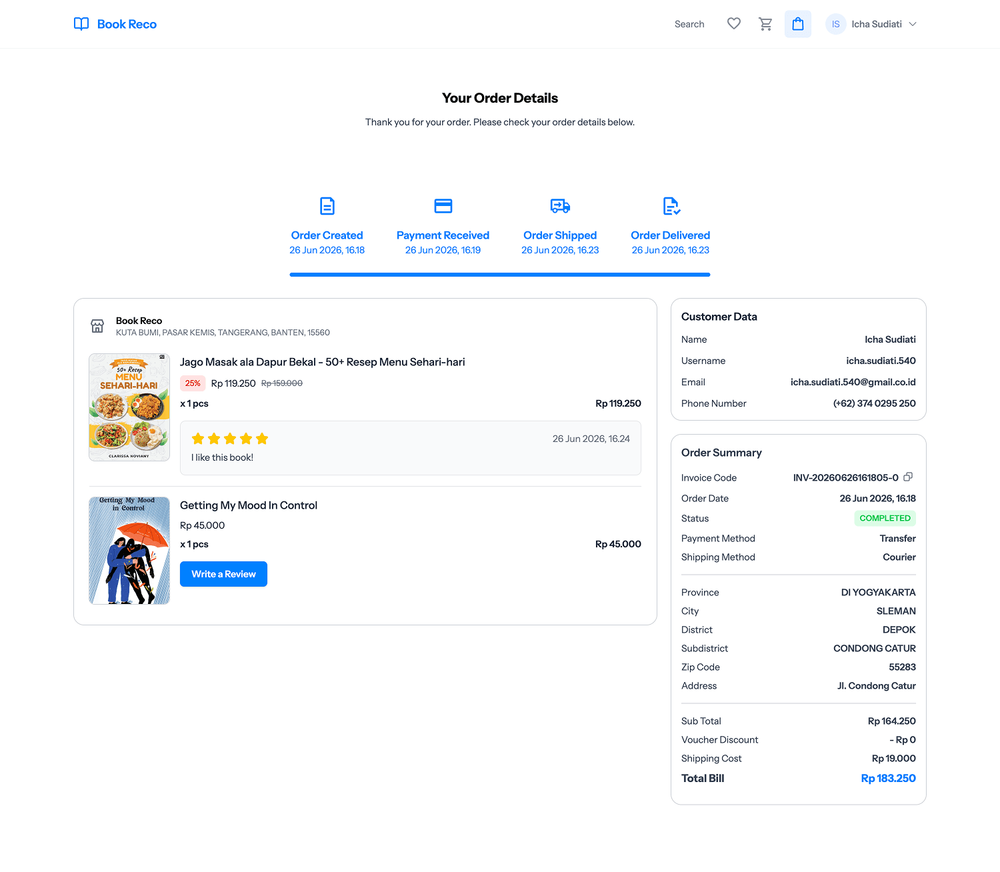
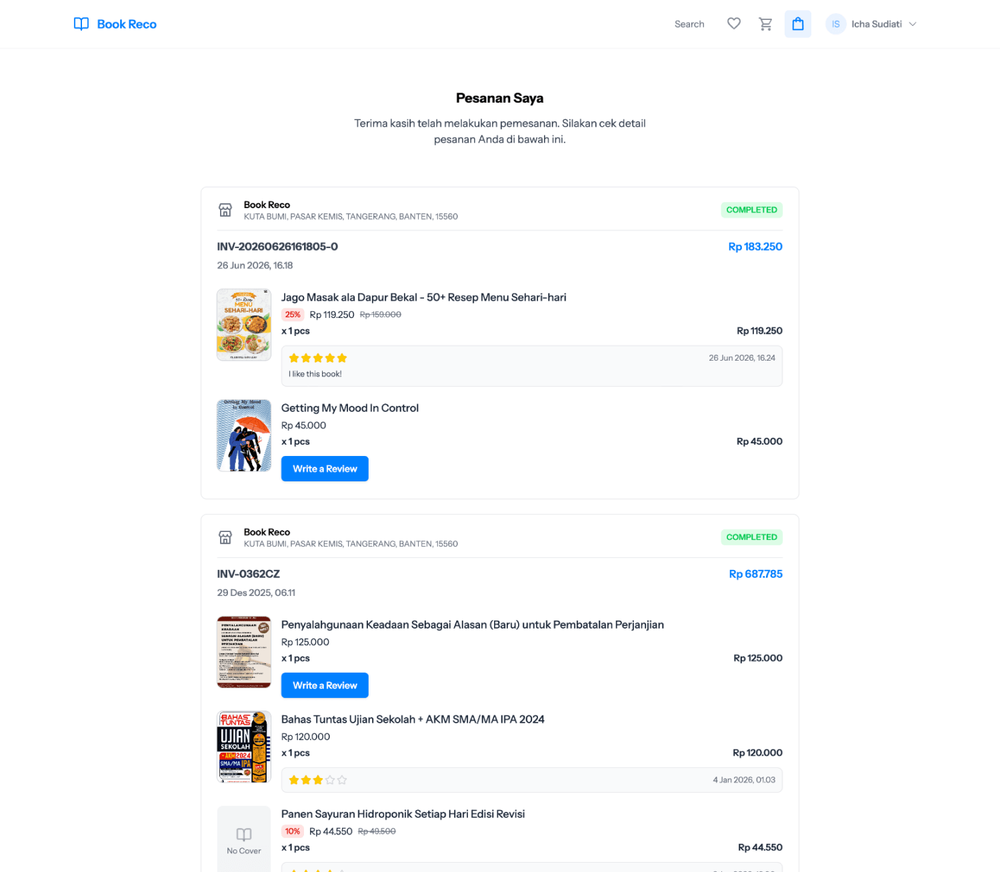
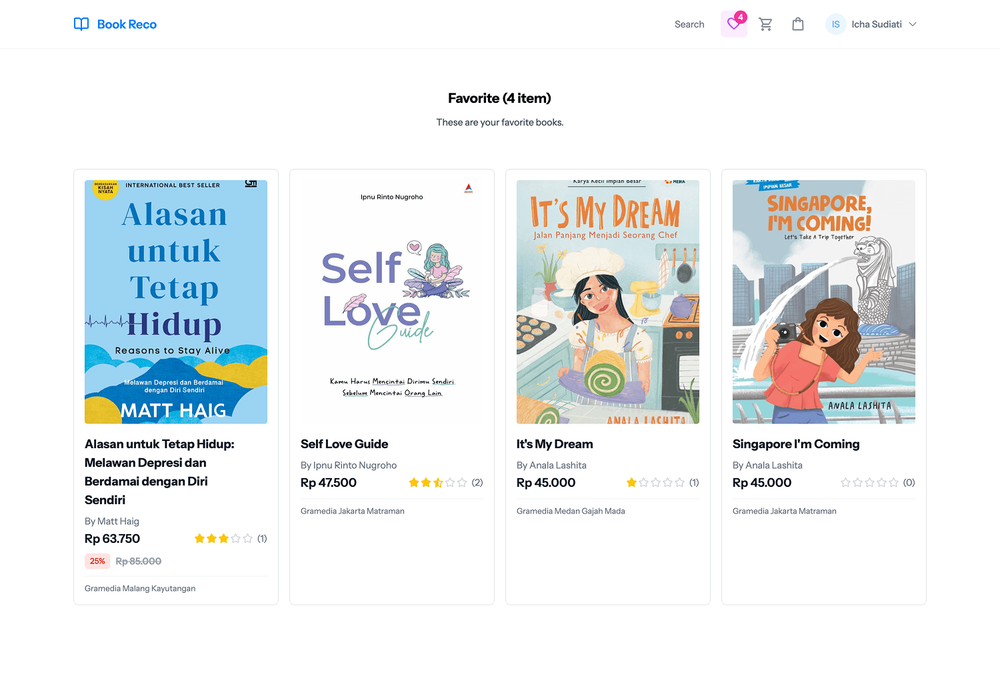
User Side Screenshots
Admin Side Screenshots

Sahid Anwar
Backend Engineer
Let's connect! Feel free to reach out for collaborations, inquiries, or just to say hi!